




Five Underused Data Science Tips to Help You Leap Over Your Competition
They’ve Worked for Me, and They’ll Work for You

Data science is a profession that is still inventing itself. This makes it extremely interesting, creative, and even magical. Thirty years ago, you wouldn’t be called a data scientist, that term did not exist. You probably wouldn’t be called a machine learning engineer or data engineer. It was a lot less flexible back then. You were bound by a curriculum revolving around classic statistics or actuarial sciences, focusing on things like p-values, probabilities, linear regression, survival models, the null hypothesis, measuring representative samples, etc.
Today, a lot of that has changed. We have more processing power and distributed algorithms allowing us to feed just about any amount of data into a model. I would still recommend a strong statistical foundation, especially if you’re going to tackle large-scale surveys or design medial studies.
Everything I’ve said so far isn't’ going to help you “leap” over the competition as it is the same stuff that everybody else is learning. So, here are 5 tips, to differentiate yourself from the herd and the best part, they aren’t hard to learn.
I’ll start each tip with a question to test you and follow it up with a link, if I have one, to dive deeper into that topic.
Tip #1: Can You Translate an AUC Score Into a Dollar Amount?
If you say yes, you’re leaps above the pack, move on to the next question. If not, hang around and I’ll show you an easy way of doing it.
A statistical score is absolutely useless for an end-user — useless to most of the world. Now a dollar amount isn’t useless. It’s the lingua franca of business; everybody understands it and uses it when evaluating purchases. Most companies have somebody that can do that, probably a financial analyst or the CFO, whatever, and you should add your name to that list.
Let me give you one example using the confusion matrix, though there are plenty of other ways to figure out the cost of implementing a model. A confusion matrix breaks down the results of a model in categories such as true positives, false positives, true negatives, false negatives.
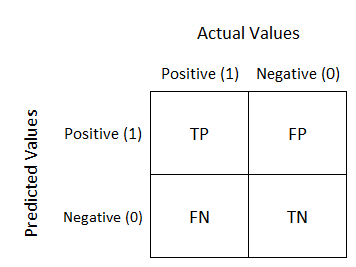
We’ll focus on true positives and false positives. So, if you have a medical model that returns 3 high-probability cases for each actual sick patient, the hospital knows that it will need to review 3 patients to find an actual sick one. All they have to do is tally the cost for the clinic, nurses, doctors, technicians, phlebotomists, lab/analysis work, etc. for 3 patients and there you have the cost to find and cure one patient using your model.
For more information, check out “The Confusion Matrix — The Ultimate Nerd-to-Executive Translator — 5 Minutes for Data Science”

Tip #2: Can You Translate a Model’s Prediction into Actionable Insights?
What is the point of a model if it can’t be translated into something actionable? None whatsoever, unless it’s a hackathon or Kaggle competition. This follows along the same lines as the first question but is a whole lot more important. Whatever the model returns, it has to be translated into something actionable for the end-user. All production models will do that in one form or another. In a lot of cases, the predictions are passed on to another analyst that will package it into a report and pass it to a subject matter expert (SME) to be disseminated into the field. Something along those lines. This is something you should be involved in. This is happening and it is critical for your education and career that you get in on that action.
If you need to sell a model to your team, to another department, or to a customer, you will need to explain what are the important features, what are the edge cases, what, at the observation level, may cause a case to be high probability. All this information is then used to create actionable insights.
Here is a video I did that extracts actionable insights from student scores to help the lagging one and this is done with both a classification model and a post-analysis at the observation level to see which features are different from the other students. Some of these differences may very well tell you what kind of help a student needs.

Tip #3: Can You Port Machine Learning to the Web?
Somebody may tell you that it isn’t your job, it’s too complicated, it’s beneath you, whatever — ignore them. If you get involved in that process beyond the machine learning or data science, you will start seeing the “big” picture. This is a critical aspect to not only extend your own knowledge, your utility in the design and deployment process of projects, but also will allow you to start your own business, startup or consulting. This is what allows you to do stuff on your own!
I have made many videos on porting ML to the web using my favorite web full-stack pipeline comprised of Python, Flask, and HTML5. The value in extending your ML projects beyond the confines of a Jupyter notebook to the web means that everybody with an internet connection will be able to enjoy and learn from your work. Think about it, there’s are a few dozen million on Github and only a fraction of those may be familiar with the programming language you are using while the number of people connected to the web is over 4 billion! I’ll let you do the math there…
I have a stripped-down example just for you where I extend a simple financial forecasting model from a Jupyter notebook to the web!
Tip #4: How Well Do You Know Your Customer?
I know plenty of data scientists and programmers that never see their customer or end-user. Some even consider that a perk of the job. Let me tell one thing, who do you think makes more money in a company, the programmer, the data scientist or the salesperson? It’s the latter, they’re not bound by a salary, they work on commission so the sky is the limit. And do you know what they do well? Yep, they know their customers well.
It isn’t just about the money, it is also, and probably more importantly about the quality of the work. There is no way you can build a good model without truly understanding your customer's needs and pains. I never work on projects anymore where I don’t consider the customer as part of my team. This includes plenty of design interviews, weekly standups, sharing of source code, progress, and training them during a release. And this relationship doesn’t end there. You can do field visits, get feedback from real users, measure how well the model is performing, look for areas to improve and mitigate model drift.
I don’t have a video on this, but my tip is for you to ask your boss or manager to sit in on meetings with your customers. Do that as early as possible in the project timeline. You may feel clumsy at first, say the wrong things, but you will get it eventually and it will be all second nature. Once you start doing that, you will never be able to work in a vacuum again and the quality of your work will leap above your peers.
Tip #5: Do You Compete on Kaggle?
This is where I “cut my teeth” learning data science. Most of what I learned initially came from there. I started competing even before I got my degree in data science. Actually, it is funnier than that, when I attempted my first competition, something around Facebook, I didn’t know anything about the Python or the R programming language. I was fresh off wall Street as a quantitative developer and was knee-deep into high thread and low-latency C# programming. So my first competition was done using C#. It sucked as I had to invent a lot of things the others took for granted like data frames and pre-packaged modeling algorithms.
Nevertheless, I fell in love with modeling. I promptly learned R and Python and started competing at a level playing field. I never got a gold medal but got plenty of silver and bronze ones earning me the “Competitions Expert” title.
I don’t have the time to compete anymore but it was there when I needed it the most and the community was so generous with their time that I will be forever grateful.
No video link here either except for this tip — get an account right now if you haven’t already got one and compete!

Follow my latest projects at ViralML.com, and amunategui.github.io and be sure to sign up for my newsletter!
Originally published at ViralML.com

